

테슬라의 AI 파트 시니어 디렉터인 Andrej Karpathy가 컨퍼런스에서 발표한 내용중 극히 일부를 발췌했습니다.
17분 부터 보셔도 됩니다..
현재 상용화된 자율주행은 신경망에 전적으로 의지하지 않습니다.
소극적으로 도입하는 편인데, 이유는 안정성과 신뢰성 때문입니다
신경망을 소극적으로 적용했더라도 단순한 차선을 인식해 벗어나지 않고 따라가는건 이미 상용화 된지 오래되었습니다.
그러나 여전히 제대로 보이지 않는 곳까지 예측해내는 인간의 인지능력과는 비할 수 없을 정도로 뒤떨어집니다.
테슬라도 이전까지의 1.0 코드는 신경망을 소극적으로 사용했고, 사람이 일일이 짜 둔 부분이 많습니다.
그러나 적극적으로 신경망을 이용하는 2.0 코드로 점점 대체해 나가는 중입니다.
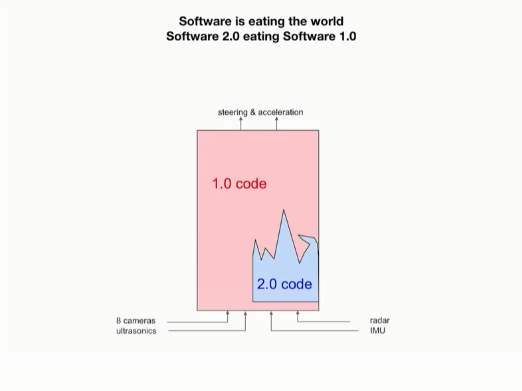
소프트웨어의 입출력은 같으나 내부 코드는 신경망을 적극적으로 활용하는 2.0 코드로 대체되어 갑니다.
일론은 앞서 이것을 오토파일럿 리라이트라고 부르며, 근본적으로 커다란 변화를 가져올 것이라 말한 바 있습니다.
코드가 충분히 대체되고 검증되면 일반 테슬라 운전자들에게도 배포가 되겠지요.
신경망을 적극적으로 활용하여 어떤 변화가 일어났을지 살펴봅시다
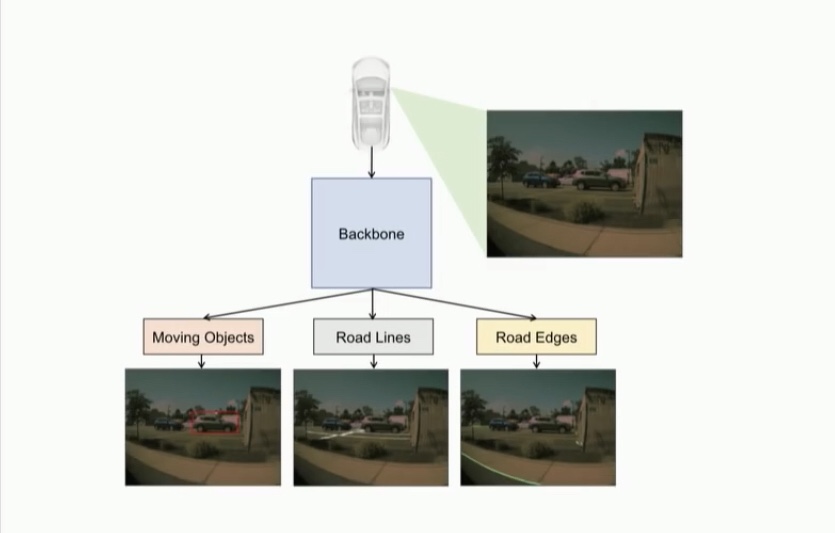
자율주행차는 여러개의 카메라로부터 얻은 자료를 바탕으로
사물 / 차선 / 도로의 경계를 추출합니다.
테슬라는 주차장에 있는 차가 주인에게 스스로 천천히 이동하는 스마트 호출 기능을 제공하는데,
이때 로컬 지도를 그리기 위해 경계 추출을 사용합니다.
기존의 경계 추출을 볼까요?

위와 같이 여러개의 카메라로부터 투사한 2D이미지 정보로 도로 경계를 얻고
기존의 소극적으로 신경망을 활용한 1.0 코드를 이용해 이어붙여 조감도로 만들면 아래와 같은 결과물이 나옵니다.

저렇게 카메라의 이미지 변화를 통해 점진적으로 아주 작은 즉석 지도를 천천히 생성해 도로를 구분하고 경로를 찾아내어
GPS에 표시된 주인에게 천천히 가는 것이지요. 기존의 SLAM을 보는것 같네요
여기에는 문제점이 있습니다.
우선 카메라들이 임의의 방향으로 배치되어 있는데, 여기서 얻어낸 2D 이미지로 측정한 경계가 서로 일치하지 않기도 합니다.
그래서 기존 방식대로 사람이 초기 파라미터를 조절해 에러없이 제대로 작동하는 코드를 짜기 어렵습니다.
게다가 카메라에서 투사한 2D 이미지에 그대로 의존하기 때문에 보이지 않는 부분을 사람처럼 예측하지도 않고
멀 수록 정확도가 떨어지기 때문에 충분한 크기의 즉석 지도를 생성하기 어렵습니다.
마치 주위 2m만 보이는 사람처럼 길을 찾게 되기 때문에 답답하고 느립니다.
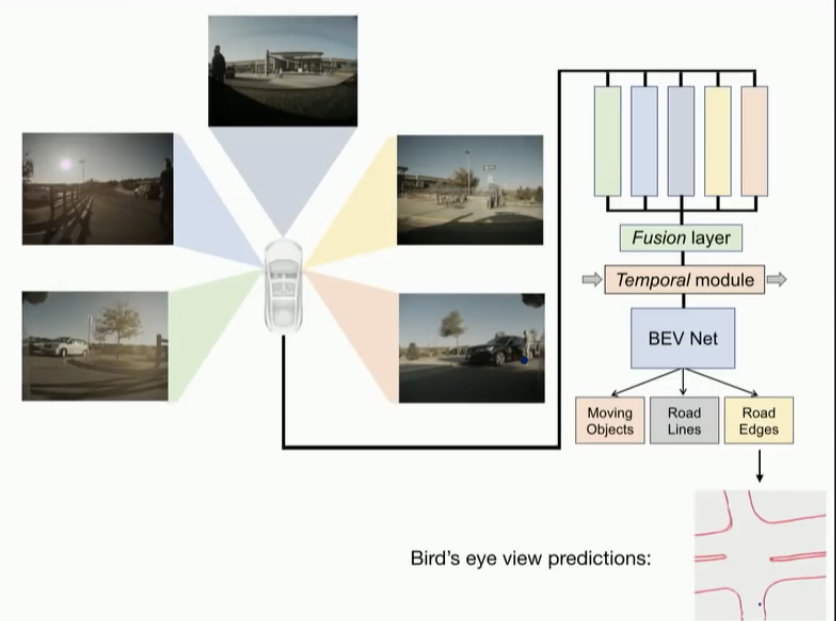
위는 신경망을 적극적으로 활용하는 2.0 방식입니다
각각의 카메라의 2D 이미지를 새로 개발한 fusion layer라는 신경망에 집어넣어 얻어낸 특징지도를 이어붙이고 조감도를 생성합니다.
이후 다른 신경망 모듈을 통해 다듬은 다음 다시 디코더에 넣으면
정확히 측정할 수 없는 부분도 예측하여 생성된 조감도를 얻을 수 있습니다.

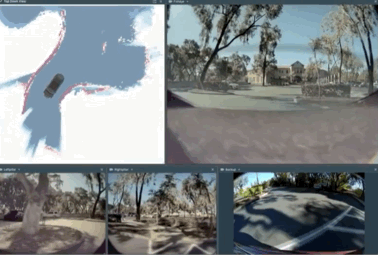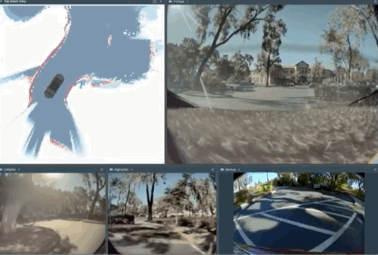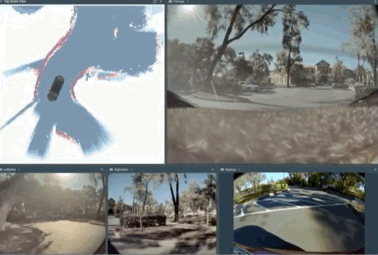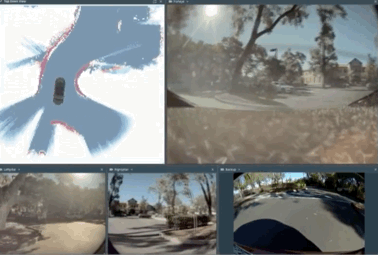
실측값 / 2.0 코드 / 1.0 코드 에서 얻어낸 이미지 입니다.
파란 점은 차량의 위치입니다.
오른쪽의 1.0 코드 기반의 이미지를 보시면 카메라에서 얻어낸 이미지에서 경계를 측정하고 단순히 뿌려서 얻어낸 조감도는
차량 주위만 정확할 뿐 도로의 수평선 경계로 갈 수록 정확도가 형편없습니다.
카메라에서 수 픽셀의 차이만으로도 수 미터의 오차가 발생하기 때문입니다.
반면 중앙의 2.0 코드로 그려낸 조감도는 실측 데이터와 거의 유사할 정도로 뛰어납니다.
카메라로는 정확히 측정할 수 없는 부분까지 높은 정확도로 예측하고 있지요.

2.0 코드 기반이 실제로 어떻게 쓰이는지 나타낸 것입니다.
참고로 밑의 4개 그림은 참고로 해당 신경망을 활용하여 도로경계, 차선, 차선의 속성, 교통흐름, 교통량 등을 각각 그려낸 정보입니다.
보시면 교차로에서 우회전을 하는데, 상당히 먼 곳 까지 실시간으로 그려내는것을 볼 수 있으며 이는 아주 강력하다고 합니다.
아래는 코드 2.0을 이용하여 스마트 호출로 주차장에 있는 차량이 주인에게 찾아가는 영상입니다.

카메라의 이미지를 토대로 제대로 보이지 않는 부분까지 예상하여 조감도를 그려냈고
주차장의 입구를 빨간색으로 표시하고 있습니다.
덕분에 원하는 곳을 가기 위해 어디서 우회전을 해야 할 지 미리 알 수 있게 되었습니다.
신경망을 이용한 예측을 적극적으로 활용하자 기존 방식으론 불가능했던 것들이 가능해지네요.
테슬라는 어렵지만 근본적인 해결책을 추구하는것으로 보입니다.
인간과 동급의 인지, 예측 능력을 차에게 부여하는 것이죠.
현재 다른 기업들은 차선이나 연석등의 정보를 센티미터 단위까지 상세히 표현하는 3D 고정밀 지도를 제작하여 차량에 담고 라이다까지 동원하여 자율주행을 시연합니다.
일례로 평창에서 왕복 7km 자율주행을 시연했던 넥소의 경우 차량에 라이다 센서는 물론 200GB의 정밀 지도가 탑재되어 있었습니다.
현대는 미래의 자율주행을 위해 전국 정밀 지도를 제작중이고,구글 웨이모의 차량도 고정밀 지도를 활용합니다
자율주행차가 도로를 사람 수준으로 인지하도록 발전시키는것 보다 정밀 지도를 만들어 집어넣는게 당장에는 더 쉬울수 있겠지만.
진정으로 인간 운전자를 대체하려면 결국 사람과 버금가는 수준의 인지능력이 필요해질 것이라는 생각이 드네요.
저 이후에 스테레오 카메라로 얻은 depth 이미지를 이용해 라이다로 얻은듯한 3차원 맵을 생성하고 이걸 다시 각각의 카메라 위치로 프로젝션 한 다음. 실제 카메라에서 받아들여지는 이미지를 대조하여 자기 지도 학습을 하는것도 있습니다만 내용이 너무 길어져서 뺐습니다.
Pseudo-lidar 라고 하던데 해당 문헌 기반이라는듯 합니다. https://arxiv.org/abs/1906.06310




 임시닉네임
임시닉네임






 책읽는달팽
책읽는달팽

 MUGEN
MUGEN




