

얼마 전에 라이젠 3900X에서 인텔 컴파일러 사용시 성능 저하가 없는가에 대한 질문을 했는데.
결국 시스템 빌드해서 직접 테스트 해봤습니다.
결론부터 말씀 드리자면 라이젠에서 인텔 컴파일러, 포트란 및 MKL은 정상 작동 했고, GNU 컴파일러와 비교 했을 때 거의 성능 저하가 없었습니다. (단, Intel VTune™ Amplifier는 설치 중 사용이 불가능하다고 나왔습니다.)
그리고 나온지 얼마 안된 라이젠이라 리눅스에서 많이 불안정 할 줄 알았는데 생각보다 오류 없이 잘 작동 되었습니다.
한 가지 문제가 있는 게 lm-sensor로 CPU 온도 모니터링 할 때 오래된 커널을 쓰면 온도 모니터링이 안됩니다.
저는 CentOS 7와 Ubuntu 19.01을 설치했습니다. CentOS 7의 경우 처음 설치 시 3.10 커널이 설치되는데, 해당 커널에서는 3900X 보드의 온도 센서에 대한 드라이버 모듈이 없어서 온도 모니터링이 안됩니다. 4.9 이상으로 커널을 업데이트 시켜야 합니다. (근데 문제는 측정 되는 온도가 정확한 온도인지는 의문이 생깁니다. 윈도우 처럼 Ryzen Master 이외의 HW 모니터링 소프트웨어에서는 Ryzen Master 보다 온도가 높게 나오는 현상이 발생 하는 것 보면... ㅎㅎ)
우분투 같은 경우도 18.04 장기 지원 버전을 계속 썼었는데, 19.10로 설치 해봤는데, 설치 시 NVIDIA 드라이버도 자동으로 잡아주고 상당히 괜찮더라구요 다음 장기 지원 버전 나오면 바로 갈아 타야겠습니다. Ubuntu에서는 Intel Parallel studio 버전을 여러 개 쓰기가 좀 곤란해서 CentOS에서 벤치 마크를 해봤습니다. Computational Chemistry에서 주로 사용 되는 여러가지 소프트웨어들로 벤치 마크 했구요, CPU 오버 클럭 없이 2열 수냉에서 풀 로드시 75도 이하에서 머물더라구요, 물론 반나절 이상 연산 작업 돌리면 아마 80도 이상 찍지 않을까 싶네요.
먼저 GAMESS라는 프로그램은 포트란 컴파일러를 사용하고, BLAS를 Math library로 사용해서 작동합니다. GNU 포트란(gfortran) 또는 인텔 포트란 또는 AMD전용 포트란 컴파일러(AOCC)와 여러가지 Math library들을 조합해서 GAMESS를 빌드 해서 성능을 비교 해봤습니다. 다양한 컴파일러에서 빌드 된 프로그램을 가지고 동일 시스템에서 동일한 분자 구조에 대한 연산 시 걸리는 시간을 측정해서 비교 했습니다.
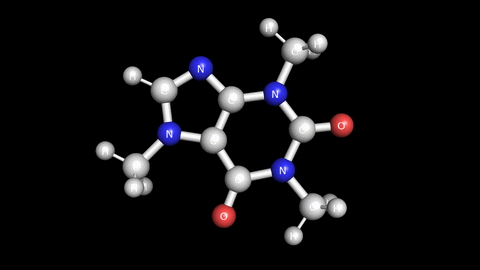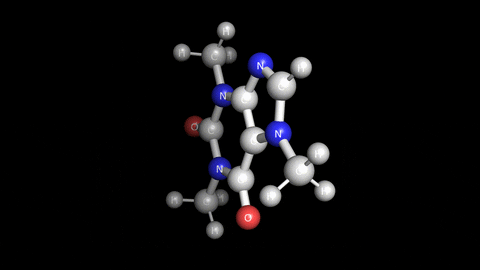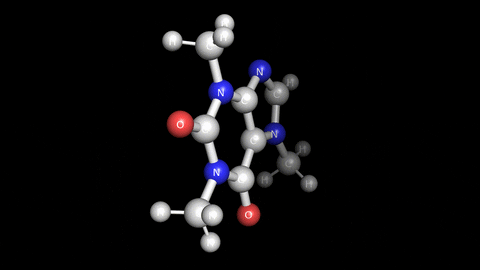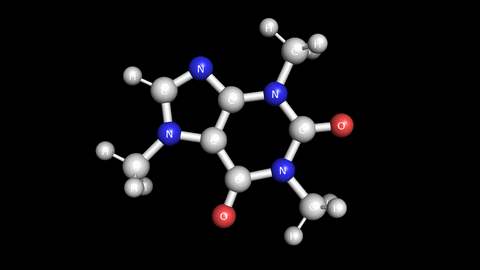
첫번 째 벤치 마크는 아래 보시는 것 처럼 커피에 함유된 "카페인"의 분자 구조를 가지고 벤치 마크를 했습니다. 비교적 작은 분자 구조이고 single point energy 계산이기 때문에 연산은 수십 초 안에 끝납니다.

벤치 마크의 2번째부터 7번째를 데이터를 보시면 거의 오차 범위 내로 비슷한 결과를 보여 줍니다. Intel Fortran + MKL 조합과 AOCC + LibFlame 조합에서 미묘하게 더 빠른 것을 보실 수 있습니다. 나머지 데이터들은 다른 프로그램들에서 연산한 결과입니다. 참고로 GAUSSIAN 16의 경우 최신 Revision 버전이 아니면 Ryzen 3900X에서 작동하지 않는다고 합니다. 쓰레드리퍼 1세대 2세대에서는 잘 작동 했던 걸로 기억하는데, CPU에 무슨 변화를 준 건지 호환이 안된다고 합니다....
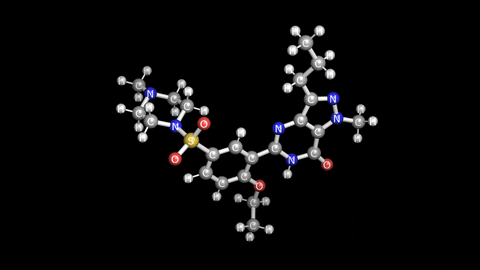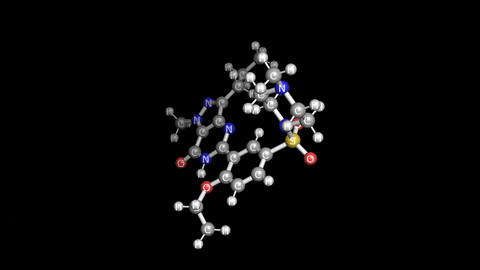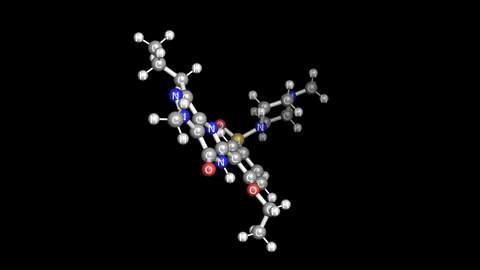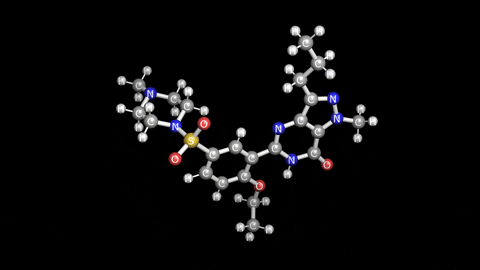
두번 째 벤치 마크는 좀 더 원소가 많은 "실데나필"이라는 분자 구조를 가지고 Single point energy 계산으로 벤치 마크를 했습니다. 해당 구조는 아래 그림에 보이는 비아그라로 잘 알려진 의약품의 분자 구조입니다. 불끈 불끈..ㅎ 아래 표의 2번째 부터 7번째 데이터를 보시면 역시 비슷한 성능을 보여주는 것을 볼 수 있고, Intel Fortran과 MKL 조합에서 약 30초 정도 미묘하게 좋은 성능을 보여 주는게 인상적입니다.

다음 프로그램으로는 Quantum Espresso라는 프로그램으로 벤치마크를 했습니다. Quantum Espresso는 CPU 연산 이외에도 NVIDIA-CUDA (GPU)를 사용한 연산도 가능합니다. Quantum Espresso를 CPU와 GPU로 나눠서 빌드를 했습니다. GPU의 경우는 PGI 포트란을 이용 해서 빌드를 해야 합니다. 아래 그림처럼 니켈 결정 구조를 가지고 연산을 했습니다.
아래 표에서 CPU 빌드의 경우 Intel 조합이 GNU 조합과 비교해 볼때 유의미한 수준의 성능 개선을 보여 줬습니다.
CUDA (GPU) 빌드의 경우 PGI 컴파일러 내부에 있는 Math Library를 사용해서 빌드한 것과 Intel MKL 사용해서 빌드 했을 때와 거의 비슷한 성능을 보여 줬습니다.
(OpenMP이외에도 OpenMPI나 Intel MPI를 사용해서 Quantum Espresso 빌드를 시도 했었는데 뭔가 오류가 났는지 제대로 되지 않았습니다. MPI는 후에 다시 빌드해봐야 할 것 같습니다.)


마지막으로는 Molecular Dynamic 소프트웨어 몇가지를 벤치 마크 해봤습니다. AMBER 18의 경우는 CPU용 으로 빌드를 할 수도 있지만 GPU용 으로만 빌드를 했습니다. 히스톤 디아세틸레이즈 2(HDAC2)라는 단백질 효소를 가지고 벤치 마크를 했습니다. GNU 컴파일러와 Intel 컴파일러에서 동일한 거의 성능을 보여 줬습니다.

몇 몇 소프트웨어들이 컴파일 시에 인텔 CPU에서와 다르게 작동을 안하는 것들이 발생을 했습니다. 특히 Intel MPI 관련된 것들이 문제를 일으켰는데 아마도 Intel parallel studio 2019 버전을 사용해서 그런 것 아닐까 추측해 봄니다. 주로 2017이나 2018 버전으로 소스들을 빌드 하곤 했었는데 이번에는 라이젠이라 웬만하면 다 최신으로 쓰려고 하다 보니 문제가 생긴 게 아닌가 생각됩니다. 2017이나 2018 버전으로 다시 빌드 해봐야겠습니다.
위의 벤치 마크 결과를 보시는 것처럼 Ryzen CPU에서 Intel 컴파일러를 사용해도 성능 하락이 없는 것을 확인 할수 있었습니다. Intel developer zone에 AMD CPU에서 인텔 컴파일러 성능이 어떠냐고 물어보면 성능 하락이 있다고 하곤 하는데 Ryzen 3000에 대해서 보면 그렇지도 않은 것 같습니다. GAMESS는 AVX"2"를 사용하는지 모르겠지만 Quantum Espresso나 AMBER는 AVX2를 사용합니다. Ryzen 1000에서는 AVX2가 반 토막 짜리라 성능 하락이 있었었는데, 3000에서는 그렇지 않은 것 같습니다.
워크스테이션이나 소규모 클러스터 용으로 라이젠 3000 시리즈도 쓸만 한 것 같습니다. 새로 나올 쓰레드리퍼가 기대가 많이 되네요.






















