기글 하드웨어 스페셜 게시판

출처 : http://www.anandtech.com/video/showdoc.aspx?i=3507&p=8
사용하는 시스템이 하이엔드이건 로우엔드이건, 누구든 현실에 가까운 실시간 3D기술이 실현되기를 기대합니다.
그를 위한 발전의 원동력은 순수한 하드웨어 성능과 괄목할만한 기술의 발전들을 포함한 복합적인 요소들이며, 이로 인해는 점점 더 우리가 실제로 보는 것에 가깝게 나아갑니다.
하지만, 이 방정식의 이면에는 개발자들과 하드웨어 이외의 또다른 요소가 존재합니다. 바로 그래픽 API입니다.
CPU와 달리, GPU는 하드웨어의 성능을 쉽게 사용할 수 있도록 하는 공통 명령어를 가지고 있지 않으며, 우리가 이러한 것을 바람에도 불구하고 아직은 그 어떤 GPU도 이를 실현하지 못했습니다. Aplication Programming Interface를 통를 통해 코드를 생성하고 칩이 사용가능한 명령어로 변환하는 것은 그래픽 하드웨어 디자이너들의 몫입니다. 왜냐하면 개발자들과의 유일한 접촉점이라고 할 수 있는 그래픽 API가 믿을 수 없을만큼 중요하기 때문이지요.
이는 곧 프로그래머들이 하드웨어를 얼마나 유연하게 사용할 수있고, 얼마나 3D그래픽이 현실에 가까워질 수 있는지를 의미합니다.
그래픽 API에 의해 구현되는 핵심사항 중 한가지는 3D세계의 3D 물체들을 설명하여 이 물체들과 함께 다른 요소들을 하으웨어를 보내고, 하드웨어가 이를 어떻게 해야할 지 지시하는 것입니다. 이를 위해서 흔히 파이프라인이라고 부르는 순차적 프로세스가 수반되어야 합니다. 그래픽 API의 파이프라인에는 각각 다른 작업이 수행되는 단계들이 존재합니다.
먼저 버텍스 데이터(형체의 모서리 위치의 정보입니다)가 처리됩니다.
그 다음에 이 형체를 조종할 수 있게 되며, 혹 필요할 경우는 재 연산을 하게 됩니다. 이 다음에는 3D 형상을 픽셀이라고 부르는 2D 조각으로 변환하여, 텍스쳐 정보를 열람하거나 라이팅 기술 등을 통해 처리됩니다. 픽셀들의 연산이 끝나면 이는 화면에 출력됩니다. 그리고 지금까지 이야기 한 것이 3D그래픽 작업의 개략적 과정입니다.
지나온 약 12년간(더 오래된 것처럼 느껴지지만), 그래픽 하드웨어 개발자들은 두가지의 두드러지는 API를 통해 그래픽 하드웨어를 발전시켜 왔습니다. 바로 OpenGL과 DirectX입니다.
이미 지난번의 OpenCL관련 기사에서 곁길로 새어 OpenGL에 관련된 내용을 이야기 한 바 있으나, 이번에는 DirectX에 초점을 맞추도록 합니다.
마이크로소프트의 그래픽 API인 DirectX는 OpenGL에 비해서 게임 엔진에 훨씬 자주 쓰이는데, 이는 DirectX가 훨씬 더 빨리 동작하는 경향이 있고, 하드웨어와 DierctX의 유연성과 명령어들을 위한 지렛대역할을 하기 때문입니다. 다이렉트X의 업데이트는 곧 앞으로의 하드웨어의 성능을 결정하게 되고 개발자들에게 향상된 도구들을 제공하는 것을 의미하므로 항상 이야깃거리가 됩니다. 다가오는 다이렉트X는 미래의 그래픽을 짐작할 수 있게 합니다. 현재 발매되거나 개발중인 많은 다이렉트X 9/10 기반의 게임들이 존재합니다만, 미래의 지평을 만들어 나가는 것은 다이렉트 11입니다.
항상 그러듯이, 마이크로소프트는 호환되는 하드웨어의 발매와 다음 버젼의 다이렉트X의 배포시기를 맞추려 할 것입니다. 예전에도 그랬듯, 다이렉트X는 윈도우즈7과 동시에 공개될 것입니다. 현재 윈도우즈 7의 베타 버전이 공개되었지만, 금년 중으로 이 OS의 개발이 끝날 수 있기를 기대해 봅니다.
마이크로소프트는 윈도우즈 비스타를 축출하는 방향으로 윈도우즈 7의 지향점을 공격적으로 잡았기 때문에, 아마 그들은 최대한 빨리 이를 완성해낼 것입니다.
다이렉트X 9과 10의 사이에는 4년이 넘는 시간이 존재합니다. 다이렉트X 10이 윈도우즈 비스타와 함께 시장에 나타난 2007년 1월 이후, 우리는 불과 2년이 지난 지금 아주 가까운 시일 내에 이의 대체품이 나오는 것을 기다리고 있습니다. 차차 알게 될 것이지만, 다이렉트X 9기반의 게임들이 주류를 이루고 다이렉트X 10이 널리 사용되기 이전인 지금 이 자리를 대체하게 되는 것은 다이렉트X 11으로서는 잘 된 일입니다.
하지만 먼저 좀 더 자세하게 언급하고 넘어갑시다.
다이렉트X 11의 소개 : 파이프라인과 특징들
이하는 다이렉트X 10의 모식도입니다.
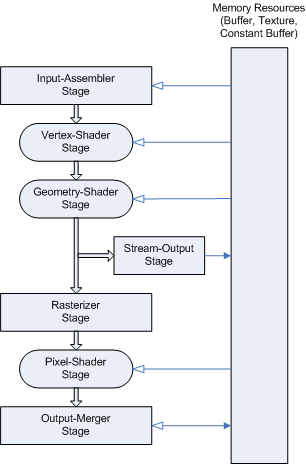
우리는 G80코어를 통해 이를 처음 접했고, 이 때는 비스타가 얼마나 엿같을지 아직 알지 못할 때였죠.
다이렉트X 10의 문제는 OS의 문제와 드라이버 지원, 시장의 제약, 그리고 다이렉트X 10이 가능하게 해 준 멋진 기능들을 개발자들이 사용하지 못했던 것입니다.
다이렉트X 11을 살펴봅시다.
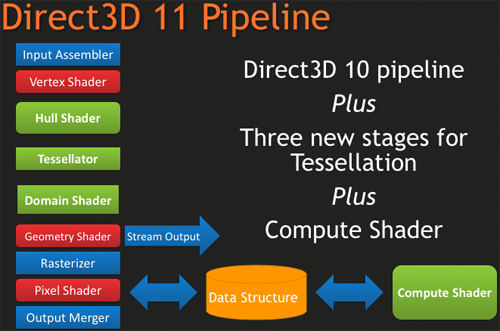
이는 예전에 비해 발전된 모습을 보여줍니다.
이 아래에 숨겨진 많은 요소들은 DX10에서 구현되었으나 잘 사용되지 않은 기능들이 더욱 뛰어난 성능을 보일 수 있도록 해 줍니다. 파이프라인에 있어 가장 큰 변화는 그래픽 하드웨어와 소프트웨어의 성능상의 발전입니다. 테셀레이션(헐 셰이더, 테셀레이터와 도메인 셰이더에 의해 이루어지는)과 연산 셰이더는 개발자들이 현실과 가상현실 사이의 거리를 좁힐 수 있게 도와줄 가장 두드러지는 발전 사항입니다. 이미 이 기능들은 여러차례 보도된 적이 있으나, DX11이 자리를 대체해 나갈(그리고 개척해 나갈) 핵심적인 요소는 다른 미묘한 변화들에 있을 것입니다.
하지만 이것들은 때가 되면 알 수 있을 것입니다.
파이프라인의 변화와 함께, 새로운 트윅과 조정 사항의 전체적인 면면을 볼 수 있습니다.
DX11은 DX10.1의 정밀한 개선판이라고 볼 수 있는데, 이는 모든 것이 이미 구현된 상태이며, DX11에서 유지될 것임을 시사합니다. 그리고 이 단순한 문제는, DX11 하드웨어들이 DX10.1을 지원하는 데 필요했던 것들(AMD만이 가능했던)을 요구한다는 것을 의미합니다. 이 트윅에 덧붙여서, 이러한 추가적인 내용들을 볼 수 있습니다.

파이프라인의 변화가 개발자들에게 다른 프로그래밍 환경을 제공함과 동시에, 위의 작은 변화들은 더욱 복잡하고 더욱 뛰어난 결과물이나 더 높은 성능을 추구할 수 있도록 해 줄 것입니다. 이와 더불어, 마이크로소프트는 게임 개발자들이 조금 더 쉽게 병렬 프로그래밍을 할 수 있도록 길을 열어가고 있습니다.
진화에서 개척까지, 그리고 멀티 쓰레딩 : 개관
12월의 DX SDK에서는 처음으로, 개발자들이 DX11의 일부 기능들을 사용할 수 있었습니다.
당연하게도 아직까지 DX11기반의 하드웨어는 존재하지 않지만, 윈도우 비스타나 7과 함께 DX10 하드웨어에서 내장된 기능들을 사용할 수 있을 것입니다.
이는 Khronos가 지난 달에 완성한 두가지의 특징을 가진 GPU 범용 컴퓨팅을 위한 OpenCL의 특징들과 결합되어 있습니다. 물론, DX11이 실시간 3D에 가깝게 지향점을 두고 있고 OpenCl은 그래픽 기술에서 떨어져서 병렬화된 범용 컴퓨팅(CPU와 GPU를 아우르는)을 지향하지만, 이 두개의 프로그래밍 API는 미래의 컴퓨팅에 있어 아주 중요한 이정표입니다.
DX11에는 단순히 연산 셰이더 이외의 것이 존재하는데, 처음으로 이를 접한 2008년의 NVISION 이후, SIGGRAPH와 GameFest 2008의 프리젠테이션을 듣고 슬라이드(이 기사의 설명을 돕기 위해 쓰인 그림의 출처)를 읽으면서 더 많은 것을 조사할 기회를 얻었습니다. 가장 흥미로운 점은 테셀레이터나 연산 셰이더의 추가 같은 것들보다 사소한 것인데, 어찌되었든 DX11의 등장은 AMD와 nVidia의 DX10/10.1하드웨어를 사용하는 이들이 드라이버 지원을 받을 수 있는 이점을 제공할 것입니다.
다양한 분석을 통해 DX11으로의 이행은 기정사실로 보이며, 마이크로소프트가 윈도우즈 7을 빠른 시일 내에 내놓는다면 이는 더욱 가속화될 것입니다.
HLSL(고차원 셰이더 언어)의 추가도 이루어져 이는 개발자들에게 큰 매력일 것이며, DX11이 DX10에의 하위 호환성을 가진다는 점은 과도기적인 암시를 하게 되어 개발자들이 이 API로 재빨리 옮겨갈 수 있게 도와줄 것입니다. DX11은 윈도우 비스타에서도 사용이 가능하므로 유저들에게 큰 지출을 요구하지는 않을 것이며, 윈도우 7은 XP 사용자들의 업그레이드를 부추길 것이므로, 이는 개발자들이 더욱 많은 타겟을 설정할 수 있을 것임을 의미합니다.
DX10은 영상분야와 렌더링 기술자들에게 혁명을 가져다 주었고, DX11은 개발자들이 API 변환을 지난 날 보아온 것보다 더욱 빨리 해 나가는 것을 가능하게 할 것입니다. 어쩌면 개발자들이 DX11의 놀라운 기능들이 가져다 줄 이점들을 제대로 활용하지 못할 수도 있지만, 새로운 API로의 이행은 결과적으로 실시간 3D 그래픽의 발전을 촉진하게 될 것입니다.
DX6에서 DX9까지의 과정을 거치는 동안, 마이크로소프트는 그들의 프로그래밍 API를 아주 단순한 기능에서부터 하드웨어를 더욱 깊이 활용함을 통해 풍부하고 프로그래밍 자유도가 높은 환경으로 이끌었습니다. DX9에서 DX10으로의 과정은 그 마지막 단계였고, 새로운 하드웨어를 통해 DX9에 더욱 깊고 유연한 프로그래밍 자유도를 더하였습니다. 마이크로소프트는 DX10기반의 하드웨어를 사용하여 안정성과 유연성을 향상시킴을 통해 과거의 유산을 버리고 DX10으로 옮겨갈 수 있게 고무하였습니다. 하지만 DX11은 다릅니다.
과거의 거푸집을 버림으로써 프로그래밍 유연성을 높이는 방향이 아니라, 마이크로소프트는 DX10/10.1의 정밀 개조판으로 설정함으로써 몇가지 재미난 가능성을 던져주었습니다. 핵심은, DX10 은 DX11의 코드가 됨으로써 몇가지 추가 기능을 사용할 수 없게 된다는 것입니다. 반면에, DX11은 이전의 하드웨어를 지원하게 됩니다. 당연히, DX11의 모든 기능을 사용할 수 는 없겠지만, 이는 개발자들이 DX11에만 매진하여 아무런 추가적 노력 없이 DX11과 DX9 기반의 하드웨어를 충족시킬 수 있다는 것을 의미하지는 않습니다. 각각의 부분집합은 하나의 기능만 지원하게 되는 것입니다. DX11만이 지원하는 기능(연산 셰이더나 테셀레이터)을 사용할 때는 별개의 코드가 필요할 것이지만, 여전히 DX11으로 이행하는 것이 이로울 것입니다.

낮은 사양의 하드웨어를 구동할 때가 중요한데, 이는 DX10에서 DX11로의 이행을 이전의 어느 때보다 빠르게 만들것입니다.
실제로, 가히 혁명적이라고 할 만한 변화없이 API의 변화만으로, 윈도우즈 7의 등장과 함께 비스타로의 느린 이행과 DX9에서의 이행이 활발하지 못했던(개발자들이나 소비자의 두 측면 모두에서)DX10을 되돌아보는 일을 끝낼 수 있을 것입니다. 두말할 것 없이 DX11으로의 이행을 가속시키는 가장 빠른 방법은 오늘날의 DX10.1의 코드들을 발전시키는 것입니다. DX11과 함께 DX10의 관점으로 보았을 때 이는 명백한 사실이지만, 게임 개발자들의 관점에서 보면 고품질의 DX9기능에 주력하고 DX10에서 가능해진 기능들은 쥐꼬리만큼 사용하여 게이머들의 DX11 하드웨어에 대한 기대를 높이는 것이 더 유리할 것입니다.
특히 DX11로의 이행에 대한 기대로 가득하기는 하지만, DX10 하드웨어에게도 혜택은 돌아오게 될 것입니다.
그 핵심은 바로 멀티 쓰레딩입니다. 물론 모든 것들은 그려지고, 레스터화 되어 출력되어(선적이고 동조적으로)야겠지만, DX11은 멀티 스레드 기능을 지원하여 임의의 갯수의 쓰레드를 통해 애플리케이션이 동시에 리소스를 생성하고 상태를 관리할 수 있게 해 줄것이며 드로우 명령어들을 추가할 것입니다. 이를 통해 하위 그래픽 시스템(특히 GPU 성능이 아주 제약되어 있다면)이 눈에 띄게 가속화되지 못할 수도 있지만, 늘어나는 데스크탑 CPU 코어 수에 힘입어 더욱 쉽게, 뚜렷하게, 방대하게 게임의 쓰레드를 증가시킬 것입니다.
8개와 16개의 논리 프로세서를 내장한 시스템이 곧 등장할 것이고, 개발자들은 그들이 현재 듀얼코어에서나 잘 돌아갈 수 있게 만든 매우 거칠고 무거운 쓰레드를 개선해야 할 것입니다. 두 개 이상의 코어에 최적화 된 게임을 개발하는 것은 개발자들의 비용대비 효과면에서 보면 대단히 손해 보는 일입니다.
대부분의 비디오 게임에서 쿼드코어에 초점을 맞춘 병렬성을 도출하는 것은 매우 어렵습니다. 하지만 다수의 코어를 통해 쓰레드를 병렬화 하는 것은 싱글쓰레드로 남는 것에 비해 많은 이점을 제공합니다. 단일 쓰레드가 모든 DX 상태변화와 드로우 요청을 처리하는 것(또는 매우 잘 정리되고 아주 부담이 큰 동조성을 요구하는 경우)에 비하여, 개발자들은 아주 자연스럽게 쓰레드를 추가하여 물체의 유형이나 집합을 관리할 수 있을 것이며, 모든 사물이나 그들 전체가 각각의 쓰레드를 가지게 되는 첩경(논리 프로세서로는 수백가의 코어가 필요한 작업을 위해)을 찾게 될 것입니다.
마이크로소프트가 DX10하드웨어에서 DX11기반의 게임들이 멀티쓰레드를 사용할 수 있도록 계획했다는 것은 매우 큰 보너스입니다.
그 유일한 제약은 AMD와 NVIDIA가 DX10기반 하드웨어의 드라이버에 다소의 업데이트를 해야 전체의 확장된 기능을 사용할 수 있게 된다는 것입니다(물론 사용은 할 수 있겠지만, 드라이버를 교체한 것에 비하면 떨어질 것입니다). 당연히 NVIDIA와 특히 AMD(이들 역시 CPU 제조사이므로)역시 여기에 관심을 가지기를 기대합니다. 더불어, 이것이 DX11하드웨어가 발매되거나 널리 이용되기 이전에 게임 개발자들이 DX11에 관심을 가질 수 있도록 도울 수 있기를 바랍니다.
이 모든 페인팅 동작들은 DX11이 쉽게 접할 수 있는 기술처럼 보이기 위한 것입니다.
추가되고 확장된 DX10과 타이밍, 그리고 이전의 하드웨어에서 동작하는 기능은 보다 빨리 사용자들을 흡수할 수 있도록 파란을 일으킬 것입니다.
상대적으로 빠름에도, 우리는 여전히 DX11이 확산되는 데는 몇년이 필요할 것으로 보이지만, 추가된 매력적인 기능들과 현재 다져진 기반들은 게임 개발자들이 DX 11으로 옮겨가는 전에 없던 동기가 될 것으로 기대합니다.
마이크로소프트가 DX11을 윈도우즈 XP에서 지원하지 않는다고 해도, 게임 개발자들은 이전의 코드를 게임에 포함시킬 필요가 없을 것입니다.
새로운 OS의 성능이 매우 뛰어나고, 사용중인 하드웨어가 그 까다로운 요구조건을 만족시킨다고 하더라도 누적된 지원들을 보더라도 꼭 과거의 OS를 등질 필요는 없습니다. 만약 윈도우즈 7이 삐까번쩍한 패키지를 두르고 나오는 좀 더 비싼 윈도우 비스타에 불과하다면, 여전히 DX9은, 특히 낮은 사양을 요구하는 캐쥬얼 게임들에게 있어서는 매력을 가질 것입니다. 매우 간단하지만 놀랄정도로 대중적인 게임들과 콘솔게임들에게 있어 실시간 3D의 진정한 가치는 범용 컴퓨팅이 대중화됨을 통해 빛을 발하겠지만, 처절할 정도의 저사양의 하드웨어(역주:기글 저사양이 아님)와 일반적인 시스템에서 API의 성능을 제한하는 것은 메인스트림에서 그래픽 발전에 저해요인이 될 것입니다.
하지만 이는 단순한 전망입니다.
이 새로운 기술에 대하여 좀 더 깊게 파고들어가봅시다.
까발리기 : DX11과 멀티 쓰레드 게임엔진
멀티 쓰레드 프로그래밍은 아직 십수년 동떨어진 기술이었기 때문에, 메인스트림 프로그래머들은 멀티코어 CPU가 나오기 전까지 병렬컴퓨팅에 초점을 맞추지 않고 있었습니다. 훨씬 많은 코드들은 싱글 쓰레드에 비해 직선적이게 됩니다. 병렬 프로그래밍을 통해 성능 향상을 도출하는 것은 어려운 일이고, 또한 항상 효과가 두드러지는 것은 아닙니다. 아주 뛰어난 프로그래머들에게 있어서도, 병렬화의 속도는 필연적으로 연속적인 코드의 비율에 의해 제한된다는 암달의 법칙 Andahl's Law는 매우 X같은 것입니다.
현재의 게임 개발에 있어서, 렌더링은 이 "필연적으로 연속적인" 작업입니다.
DX10은 GPU에서 이뤄지는 모든 다중 쓰레드를 올바르게 처리하지 못합니다. 이는 렌더러의 병렬화가 이뤄질 수 없다는 것을 의미하지는 않지만, 작업이 안드로메다로 가지 않게 관리하기 위해서 동기화시키는 비용이 필요하다는 제약이 따릅니다. 이 모든 것들은 병렬화의 이점을 제한시키고, 프로그래머의 의욕을 저하시키게 됩니다. 대신에, 두드러진 성능 향상을 이끌어낼 수 있는 다른 영역에 노력을 쏟아 붓는 것이 더 나은 발상일 것입니다.
다른사람들이 뭘 하든, 렌더러의 몇몇 과정은 연속적이어야합니다.
프로그램, 텍스쳐, 그리고 리소스는 반드시 수반되어야 하지요. 지오메트리 연산이 픽셀 프로세스 이전에 수행되어야하고, 드로우 요청이 특정 과정이 활성화되어 있는 중에 수행되어, 그 과정이 작업 종료시까지 유지되어야하는 것처럼 말입니다. 고도로 병렬화된 기기에서도, 많은 것들을 위해서는 명령어가 수반되어야합니다. 하지만 항상 명령어가 관계되는 것만은 아닙니다.
API와 드라이버의 중요성을 넘어서, 다중 문맥을 사용하고 동기화하는 확장기기를 이용하여 많은 것들을 쓰레드와 관계없는 것으로 만듦으로써, 마이크로소프트는 개발자들이 좀 더 쉽고 노력을 절감하면서도 렌더링 코드 뿐만 아니라 게이밍 코드에서도 쓰레드를 안배할 수 있도록 하였습니다. 이들 역시 DX11을 사용하는 DX10하드웨어에서 동작할 것이나, 하드웨어 최적화의 부재로 인해 성능상 많은 손실이 있을 것입니다. 그러나 코드를 다른 방식으로 쓰는 근본적인 기능은 프로그래머들이 병렬화 하는 것에 익숙하고, 또 능숙해질 수 있게 해 줄 것입니다.
DX11에서 이를 가능케 해주는 도구들에 대해 살펴봅시다.
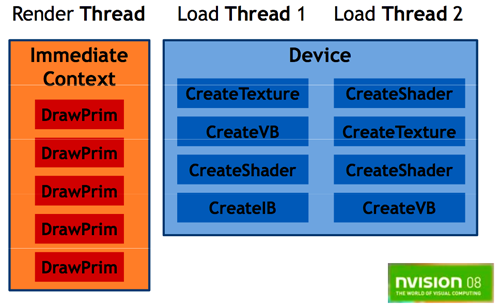
먼저 볼 것은 독립 쓰레드의 비동기적 리소스 로딩입니다.
이는 매우 작은 것입니다만, 프로그래머들이 프로그램이나 텍스쳐, 상 오브젝트, 그리고 모든 리소스들을 쓰레드에 관계없이 업로드할 수 있도록 도와주며, 원할 경우 렌더링 프로세스와 동시에 이뤄질 수 있게 할 수도 있습니다. 그러나 드라이버가 GPU에 보낼 것들을 결정하기 때문에 이것이 이상의 것들이 렌더링과 병렬적으로 처리된다는 것을 의미하지는 않으나, 우선순위를 생각해보면 더이상 개발자들이 수동적으로 동기화에서 리소스 로딩 우선순위를 고려하지 않아도 됨을 의미합니다. 다중 쓰레드는 무엇이 필요하든, 어느 때든 그것이 필요할 때 로딩할 수 있을 것입니다. 렌더링과 동시에 이 과정을 수행할 수 있다는 것은, 멀티 쓰레드를 가능케 하는 동시에 방대한 데이터를 스트림하는 게임에서 성 향상을 이끌어낼 수 있을 것입니다.
이것을 가능하게 하고 다른 쓰레딩을 위해서, D3D 기기는 디바이스 Device, 인접 컨텍스트 Immediate Context, 지연된 컨텍스트 Defered Context의 즉 세가지의 별개의 기거로 분리되었습니다.
리소스의 생성은 디바이스를 통해 이루어집니다. 인접 컨텍스트는 기기의 상태와 드로우 요청, 그리고 조회를 위한 인터페이스입니다.
디바이스와 인접 컨텍스트는 오직 한개씩만 존재합니다. 지연된 컨텍스트는 상태와 쓰기 요청을 위한 또 하나의 인터페이스인데, 프로그램 하나당 여러개가 존재할 수 있으며 쓰레드들에 분배될 수 있(지연된 컨텍스트 자체는 쓰레드 독립적인 것이 아니지만)습니다. 지연된 컨텍스트와 디바이스를 통한 쓰레드 독립적 리소스 생성을 통해 DX11은 멀티쓰레드의 이점을 얻는 것입니다.
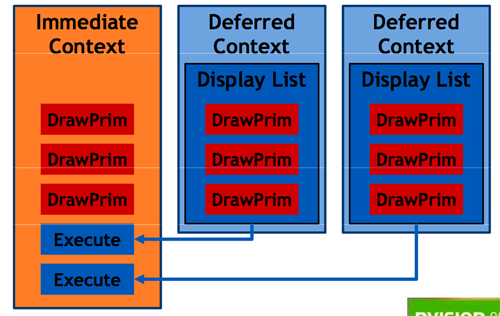
다중 쓰레드는 상태와 함께 최종적으로 인접 컨텍스트에 의해 수행된 디스플레이 목록을 따르는 지연된 텍스트에의 드로우 요청을 수행합니다.
게임은 여전히 렌더 쓰레드를 필요로 할 것이고, 이 쓰레드는 상태와 드로우 요청을 실행하고 지연된 컨텍스트에서 디스플레이 목록을 소모하기 위해 위해 인접 컨텍스트를 사용할 것입니다. 이러한 과정을 통해, 모든 상태와 드로우 요청은 최종적으로 인접 컨텍스트로 향하게 되고, API와 디스플레이 드라이버에 의해 잘 조정된 동기화를 통해 병렬 쓰레드는 렌더링에 도움을 주게 될 것입니다. 지연된 컨텍스트에는 디바이스를 조회하거나 GPU에서 다운로드 또는 읽어들일 수 없다는 제약이 존재하지만, 다른 지연된 컨텍스트에서 생성한 드스플레이 목록을 소모할 수 있습니다.
결론을 말하자면, 미래에는 좀 더 병렬화 될 것이라는 것입니다. 두개 또는 네개의 코어를 가진 CPU가 좀 더 일반화되고 8/16개의 논리 코어가 모습을 드러내게 되면, 병렬화를 통해 성능향상을 도출해내기 위해서는 지원이 필요할 것입니다.
이는 DX에 있어 매우 바람직한 시도이고, 게임 엔진들이 더 많은 수의 코어를 사용하는 데 최적화되기를 기대해봅니다.
더 까발리기 : DX11의 연산 셰이더Compute Shader와 OpenCL/OpenGL
개발자들은 연산셰이더(CS라고 불리기도 하는)에 의해 추가된 유연성에 대해 흥미를 보이고 있습니다.
이것의 추가는 파이프라인을 단순 렌더링 API에서 보다 범용의 알고리즘을 가능한 것으로 만들어줍니다. 우리는 데이터 상에서 수행되는 작업과, 수행되는 작업을 통해 이 유연성을 보게 됩니다.
다른 파이프라인 단계에서 범용 목적의 코드 수행을 가속하기 위해 지워진 제약을 보았습니다.
물론 범용 목적의 알고리즘을 픽셀 셰이더에 꾸역꾸역 밀어넣을 수는 있겠지만, 이 데이터들을 유기적으로 활용할 수 없게 되고, 단순한 작업들을 일일히 수행해야하는 고통을 겪게 됩니다.
DX11과 연산 셰이더로 들어가봅시다. 개발자들은 데이터 구조를 연산 셰이더에 잡아넣고 보다 범목적의 알고리즘을 적용할 수 있습니다.
DX10과 DX11의 파이프라인 상의 다른 완전한 프로그래머블 단계들과 마찬가지로 연산 셰이더는 단일 집단의 물리적 리소스들을 공유할 것입니다.
하드웨어는 연산 셰이더를 구동하게 될 때 지금의 것보다 좀 더 복잡해져야할 것인데, 이는 랜덤 읽기/쓰기와 불규칙 배열, 다중 출력, 프로그래머의 요구에 따른 개개 또는 그룹 쓰레드의 즉각적인 시행, 32K의 공유 레지스터와 쓰레드그룹 관리, Atomic Instruction, 동기구성체, 그리고 Unordered IO 작업을 수행할 수 있어야하기 때문입니다.
연산 셰이더로 인해 잃는 것도 있습니다.
쓰레드가 더 이상 하나의 픽셀로 취급되지 않기 때문에, (데이터 구조 안에 정의되지 않는 한)지오메트리와의 연관성이 사라지게 됩니다. 이는 연산 셰이더가 텍스쳐 샘플러를 여전히 사용할 수 있지만, 자동 삼선형 LOD 연산이 자동적이지 않을 것(LOD가 정의되어야)이라는 것입니다. 이와 더불어 뎁스 컬링depth culling, 안티 얼라이싱, 알파 블렌딩, 그리고 연산 셰이더에서 수행될 수 없는 모든 작업들이 의미를 잃는 다는 것을 시사합니다.
연산 셰이더에 의한 새로운 애플리케이션의 수는 무궁무진하지만, 게임 개발자들에게 있어 가장 매력적인 것은 픽셀 셰이더로는 그래픽 엔진에 적용할 수 없었던 간지나는 효과들일 것입니다. 이 애플리케이션들은 하이퀄리티의 안티 얼라이싱을 지원하고 독립적인 투명도를 가지는 A-버퍼 기술을 포함하여, 보다 향상된 지연 셰이딩 기술, 향상된 소용돌이와 효과들의 포스트-프로세싱, 빈도 영역의 FFT(Fast Fourier Trasform) 연산, 그리고 통합 영역 테이블을 포함합니다.
렌더링 특화 애플리케이션 외에도, 게임 개발자들은 IK(Inverse Kinemetics), Physics, AI, 그리고 다른 CPU에 특화되었던 작업들이 GPU에서 가능하기를 원할 것입니다. 데이터가 GPU의 연산 셰이더에서 처리된다는 것은, 렌더링에 쓰일 데이터가 훨씬 빨리 사용가능해 진다는 것과 동시에 일부 알고리즘들은 GPU에서 보다 빨리 작동할 수도 있음을 의미합니다. 그리고 이는 알고리즘이 두 다른 타입의 프로세서에서 똑같은 결과값을 도출해낼 수 있다면(본질적으로 대역의 측면에서 대체하게 될), CPU와 GPU모두에서 사용할 수 있음을 시사하기도 합니다.
만약 동일한 하드웨어에서 구동된다고 하더라도, 픽셀셰이더와 연산 셰이더는 매우 상이한 알고리즘을 기반으로 작동하게 될 것입니다.
눈여겨 봐야할 한 가지 사항은, HDR 렌더링에서 주로 쓰이는 노출과 히스토그램 데이터입니다. 픽셀 셰이더에서 데이터를 연산할 때에는 데이터를 고를 때나 버릴 때에 몇가지 경로와 속임수가 필요합니다. 데이터를 공유하는 것이 이러한 과정을 느리게 만들지만, 공유 데이터를 가지는 것이 여러가지 경로를 구동하는 것에 비해 빠르기 때문에 이러한 알고리즘에서는 연산 셰이더가 이상적인 것이 됩니다.
OpenCL을 살펴보면, 먼저 OpenCL은 OpenGL과 데이터 구조를 공유할 수 있습니다.
아직 게임 개발자들의 관점에서 DX11과 OpenCL을 비교해보지는 않았지만, DX11과 연산 셰이더에서 개발자들이 구현할 수 있는 기술들은 OpenGL+OpenCL에서도 가능하다는 것을 한 눈에 알 수 있습니다. 비록 연산 셰이더가 GPU 가속의 범용 컴퓨팅 인터페이스를 지향하고 있다고는 하나, 이러한 측면에서는 OpenCL이 훨씬 본래 목적에 가까우며 마이크로소프트와 DX에서 떨어진 별개의 기술이라는 관점에서는 범용 컴퓨팅을 위한 GPU 언어로서 보다 널리 확산 될 수 있을 것이라 기대할 수 있습니다.
지난 5년간 게임 개발자들 사이에서의 OpenGL의 활용도는 현저하게 감소하였습니다.
OpenCL은 DX11을 OpenGL과 연계된 프로그램처럼 사용할 수 있게 해 주겠지만, 이는 아마 CAD/CAM이나 시각화가 필요한 시뮬레이션 작업에 알맞은 기술일 것입니다.
그래서, 테셀레이터가 뭐야?
이는 지금까지의 DX11 기사에서는 다루어지지 않은 것이지만, R600에 관해 다룰 때 언급한 적이 있는 분야입니다.
R600과 R700 모두 테셀레이터를 가지고 있지만, 이들은 다분히 특화된 도구들이라 좀 더 복잡한 환경을 요구하는 DX11에서 바로 이용할 수는 없을 것입니다.
AMD와 DX의 테셀레이터는 공통적으로 자체는 프로그래밍할 수 없지만, DX11은 테셀레이터에서 입력과 출력을 할 수 있는 프로그래밍 가능한 헐 셰이더와 도메인 셰이더라는 두개의 추가적인 파이프라인 단계를 가지고 있습니다.

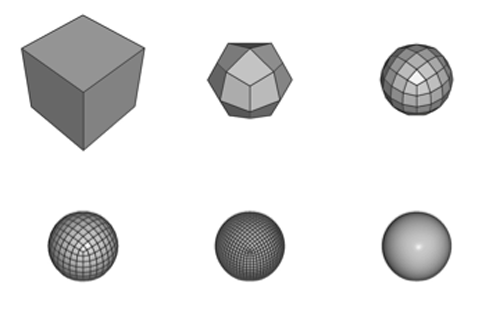
테셀레이터는 거친 형태를 쪼개서 작은 부분들로 만듭니다.
동시에 이를 조합하거나 다시 형태를 잡아서 보다 현실에 가까운 복잡한 형태를 구현할 수 있습니다. 테셀레이터는 정육면체를 아주 작은 부담과 이전에 비해 작은 공간만으로도 구형으로 변환할 수 있습니다. 품질과 성능, 그리고 안정성의 이점을 가지는 것입니다.
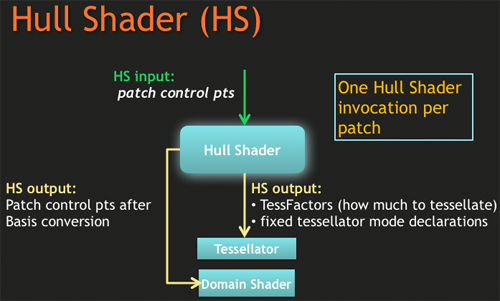
헐 셰이더는 테셀레이터를 구성하기 위해 패치Patch를 모으고 컨트롤 포인트 Control Point를 출력하고 데이터를 출력합니다.
패치는 테셀레이트할 평면의 단편을 정의하기 위한 기초(버텍스나 픽셀과 같은)입니다. 컨트롤 포인트는 지향하는 표면(커브같은)의 매개적 평면을 정의하는 데에 쓰입니다. 만약 포토샵에서 펜 툴을 써보았다면, 컨트롤 포인트가 무엇인지 감이 올 것입니다. 이들은 표면을 나타내기 위해 선 대신에 사용되는 것입니다.
헐 셰이더는 컨트롤포인트를 사용하여 테셀레이터를 어떻게 구동할지 결정하고, 이를 도메인 셰이더로 넘깁니다.
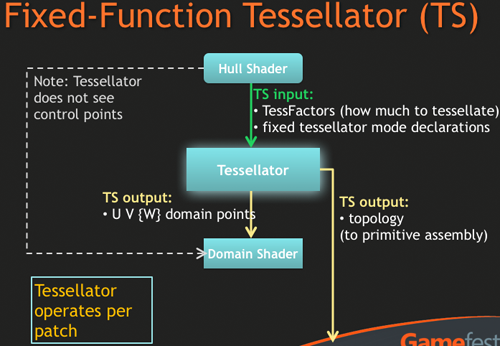
테셀레이터는 그저 테셀레이터일 뿐입니다. 입력된 패치를 각각에 적용된 헐 셰이더를 이용해 쪼개는 것입니다.
이는 연산을 종료하기 위해 도메인 셰이더로 점들을 출력해 보냅니다. 프로그래머들이 헐 셰이더를 사용하기 위해서 반드시 코드를 짜야하는 것에 반해, 테셀레이터를 구현하기 위해서는 프로그래밍을 할 필요가 없습니다. 이는 매개들에 기반하여 입력된 것을 처리하는 고정된 기능일 뿐입니다.
도메인 셰이더는 테셀레이터에 의해 생성된 점들을 컨트롤 포인트에 기반하여 알맞은 극좌표로 변환하거나, 맵map을 치환합니다.
이는 개발자가 설계한, 새로이 생성된 점들을 컨트롤 포인트와 텍스쳐를 기반으로하여 나아가 어떻게 변환하거나 치환할지를 결정하는 도메인 셰이더를 조작함으로써 작동합니다. 한 점을 계산한 도메인 셰이더는 하나의 버텍스vertex를 출력합니다. 이 버텍스들은 지오메트리 셰이더에 의해 처리고, 더 나아가 기능성을 도출해내는 버텍스 셰이더에게 제공되기도 합니다. 두번째 단계가 시행되기 전에, 대개의 데이터는는 픽셀 셰이더에 의해 지오메트리가 분해되어 화면으로 출력되는 레스터라이즈 과정이 수행될것입니다.
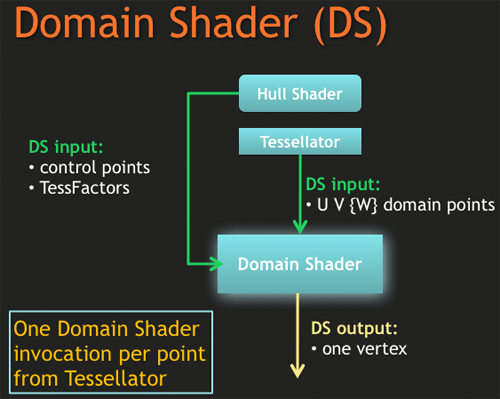
지금까지의 내용이 테셀레이터가 어떻게 작동하는지에 대한 기본이었습니다.
하지만, "지오메트리 셰이더가 테셀레이트된 평면을 생성하고 버텍스를 옮기면 되지 않느냐"라고 의문을 가지게 될 것입니다.
이는 틀린 말이 아닙니다. 기술적으로는 그러한 작업이 가능합니다만, 현실적으로는 그렇지 못합니다.
지오메트리 셰이더가 너무 굼떠서...
마이크로소프트와 AMD는 DX11이 언급되면 테셀레이션에 너무 열광하는 경향이 있습니다.
AMD는 제법 오래 전에 테셀레이션을 구현하였고, 아마 XBox 360과 같은 콘솔에서는 제대로 작동하고 있을 것입니다. 고정된 기능의 하드웨어를 도입하여 빠르고 효과적으로 메모리 관리능력을 향상시길 수 있도록 작업을 관리 하는 기술은 거실의 오락기에 가장 큰 혜택을 안겨준 것입니다. 그리고 여전히 데스크탑을 위한 테셀레이터는 사용되지 않고 있지만, 불만을 가진 사람은 없습니다.
이거 정말 빠르긴 할까요?
테셀레이터는 프로그래밍이 불가능한, 고정된 기능입니다. 물론 여기에 입력되고 출력되는 데이터는 헐 셰이더와 도메인 셰이더에 의해 조금씩 가공이 가능합니다만, 본질은 변하지 않지요. 지오메트리 셰이더는 프로그래밍이 가능한 파이프라인의 단계이고, 테셀레이션도 수행할 수 있으나, 실제로 활용할만한 수준이 되지 못합니다. 렌더링 파이프의 거의 모든 것들이 프로그래밍 가능한 영역으로 나아가고 있는 반면, 한가지에서는 구시대적 개념을 사용하였습니다. 왜일까요?
고정 기능과 프로그래밍 가능한 하드웨어 사이에서의 논쟁은 언제나 성능과 유연성의 대립에 근간하고 있습니다.
처음에는,원하는 결과물을 얻기 위해서는 고정된 기능이 필요했지요. 시간이 지날수록, 고정된 기능을 가진 하드웨어를 그래픽 칩에 추가해 나가는 것은 그다지 현실적이지 못하다는 것이 분명해졌습니다. 특화된 기능을 가진 트랜지스터는 개발자가 원하지 않는다면 그대로 쓸모없는 것이 되어버립니다. 이러한 사실이 하드웨어의 아키텍쳐가 공유가능하고 다른 작업들에 함께 사용될 수 있는 방향으로 나아가도록 만들었습니다.
하지만 일반적인 경우에서입니다. 고정기능의 하드웨어가 설 자리를 잃었다는 의미가 되지는 않지요.
개발자들이 이를 활용한다면, 테셀레이터에 사용된 트랜지스터들이 아무 의미없는 것이라고 하기에는 이릅니다.
하지만 ROI(Returen on investment : 사용하기 위해 어떤 것을 가지고 있는가)의 측면에서 봤을 때, 거대한 하드웨어는 그만큼 개발자들이 많이 사용한다는 뜻일 겁니다. 유추해보면, 테셀레이션을 위해서는, 똑같은 양의 트랜지스터를 고정된 하드웨어인 테셀레이터에 할애하는 것이 지오메트리 셰이더를 강화시키는 것보다 나은 결과를 가지고 온다는 뜻이겠지요.
이는 우리가 그래픽 칩에서 고정기능 하드웨어의 범람을 마주하게 될 것을 의미하는 것은 아니며, 미래로 나아가기 위해 발전을 도모하는 데에는 약간의 프로그래밍 유연성을 희생해야할 수도 있음을 뜻할 뿐입니다.
미래에는 대부분의 작업이 보다 높은 유연성을 가지고 수행될 것이며, 테셀레이션 또한 완전히 프로그래밍 가능해질(혹은 발전된 미래의 지오메트리 셰이더의 일부 기능으로 흡수되거나) 것입니다.
결론적으로, 고정 기능의 하드웨어에 대해 기술적인 평가를 내리는 것은 테셀레이터가 가져다 주는 이득을 이해하는 데에 아무련 도움이 되지 못합니다.
현재, 아티스트들은 그들의 오브젝트를 구현하는 별개의 LOD(Level of Detail - 대상이 가까워지거나 멀어짐에 따라 묘사의 정도를 결정함)를 위해 별개의 작업물을 생성해야 하고, 픽셀 셰이더를 거쳐야하는 각각의 LOD에서 텍스쳐링함으로써 지오메트리 시뮬레이션을 수행해야 합니다. 이 과정은 아티스트들과 프로그래머 모두에게 많은 작업을 요구하고, 성능상으로도 상당한 제약을 가져옵니다. 그리고 지오메트리를 이용해서 X빠지게 일해야 얻을수 있는 효과도 있습니다.
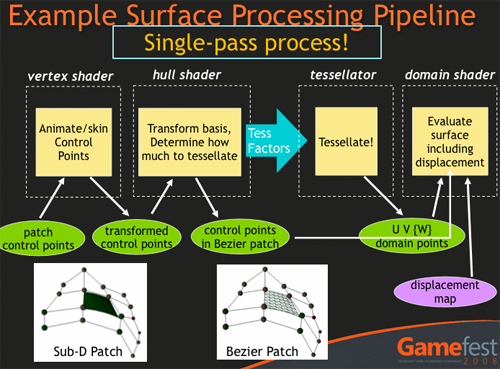
테셀레이션은 보다 정밀한 결과물과 자연스러운 그림자를 얻고 모서리를 부드럽게 하기 위한 아주 훌륭한 방법입니다.
고도의 지오메트리 또한 아주 멋진 맵의 변화 효과를 이끌어낼 수 있습니다. 현재, 텍스쳐와 범프 매핑이나 패럴랙스 오클루젼 매핑 Parallax Occlusion Mapping 외의 다양한 기법들을 통해 많은 경우의 지오메트리가 시뮬레이션 되었습니다. 고도의 지오메트리에서도, 거대한 맵에서의 라이팅 알고리즘을 사용하려고 할 때 꼭 해야할 것 만 같은 크랙Crack, 범프bump, 리지ridge, 외의 세부적인 지오메트리를 만져줄 필요가 없는데, 이는 파이프라인의 한 차례만 수행해서 테셀레이트 하고 도출할 수 있기 때문은 아닙니다. 이를 통해 빠르고 효과적이면서, 동시에 픽셀 셰이더의 일손을 덜어주어 다른 용도로 쓰일 수 있게 하여 아주 세부적인 결과물을 얻을 수 있습니다. 테셀레이션을 통해 아티스트들은 다이나믹 LOD의 부담 없이 분할 평면의 추가적 표면을 만들 수 있습니다.
간단한 헐 셰이더와 도메인 셰이더에 적용된 치환 맵이 많은 인력을 절감해주고, 결과물의 품질을 높여 줄 것이고, 성능 또한 상당히 개선해 줄 것입니다.
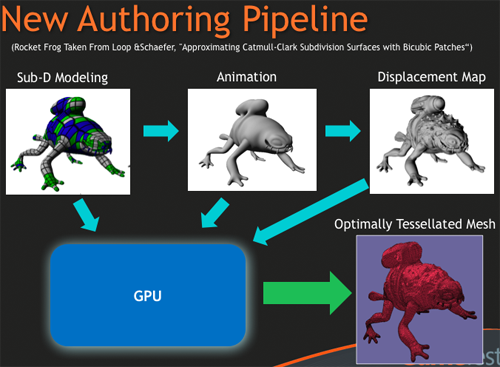
만약 개발자들이 테셀레이션을 받아들이게 되면, NVIDIA와 AMD의 DX11 지원 하드웨어들이 테셀레이션 성능을 높임과 동시에 멋진 것들을 접할 수 있게 될 것입니다. 하지만 개발자들이 테셀레이션을 바로 받아들이게 되지 않을 수도(연산 셰이더의 경우에도 마찬가지입니다.) 있습니다.
DX11은 기존의 하드웨어에서도 구동될 것이고 DX11의 발표 이전에 등장한, 명령어의 일부분을 통해 더 뛰어나고 정제된, 새로운 버전의 HLSL에 포함된 프로그래밍 언어를 사용할 수 있고 흠잡을 데 없이 병렬연산에 최적화된 무수한 하드웨어가 존재할 것이며, DX10의 하드웨어에서 구현할 수 있는 기능들만 적용한 DX11게임들이 먼저 출시될 것은 거의 명백한 사실입니다.
물론 개발자들의 관점에서 보면, 아직까지 완전히 활용하지 못했던 DX10 하드웨어를 완전히 사용하는 것은 자랑스러울만한 일입니다.
비스타의 실패로 인해 많은 사람들은 여전히 DX9의 언어를 필요로 하고 있고, 이로 인해 DX10은 완전히 새로운 것이 아니라 DX9이 조금 발전된 것으로 받아들여지는 경향이 있습니다. 따라서 DX11이 등장하게 되면, 개발자들이 DX10으로 무엇을 할 지 처음으로 볼 수 있게 될 것입니다.
물론 테셀레이션을 도입하는 개발자들도 있을 것이지만, 아마 처음에는 곡면의 각진 부분을 다듬는 데 쓰는 정도의 아주 단순한 것일 것입니다.
테셀레이션의 이점을 모두가 누리게 되기까지는 많은 아직은 많은 시간이 남아있습니다.
마지막으로 마무리하며..
마지막으로, 조금 더 개발자들의 편의를 고려한 기능들이 추가된 HLSL(High-Level Shader Language)의 버젼 5.0에 대해 이야기 해 봅시다.
지금까지의 HLSL이 통사적으로 C언어에 가까웠다면, 5.0은 계열Class과 인터페이스에 대한 추가적인 지원을 제공합니다. 하지만 여전히 포인터는 사용하지 않습니다.
이러한 변화는 셰이더 코드의 수직방향 크기로 의한 것입니다.
프로그래머들과 아티스트들은 어떤 게임이든 간에, 하나의 거대한 셰이더나 많은 수의 작은 셰이더를 생성해야합니다. 이러한 코드 리소스들은 거대하여 OOP(Object Oriented Programming) 구조 없이는 관리하기가 매우 어렵습니다. 하지만 다른 OOP 언어들에서의 작동방식과는 약간의 차이점이 있습니다.
예를 들어, HLSL에서는 (포인터가 존재하지 않으므로) 메모리 관리나 컨스트럭터 Constructor / 디스트럭터 Destructor 가 필요하지 않습니다. 초기화와 같은 작업들은 일반적으로 멤버 데이터Member Data를 반영하는 컨스턴트 버퍼 Constant Buffer를 경신함으로써 이루어집니다.

프로그래밍의 영역에 한 발짝 물러서서 보면, 어마어마한 양의 리소스와 효과들의 복잡성과 맞짱을 뜨는 동적 셰이더 Dynamic Shader 연계를 지원하기 위해 계열과 인터페이스가 추가되었습니다. 동적 연결 Dynamic Linking은 애플리케이션이 실행시간 Runtime 중에 셰이더가 무엇을 번역하고 연결할지를 결정하고, 실행시간까지 어떤 데이터를 미처리 된 상태로 남겨둘지를 결정합니다. 실행시간 중에 셰이더는 연결된 것에 따라 동적으로 연결되고, 가능한 기능들이 변환되고 최적화됩니다. 변환된 하드웨어 내장의 코드는 적절한 셰이더 기능에 의해 요청되기 전까지는 연결되지 않은 상태로 존재하게 됩니다.

이는 "if" 무수히 남발된 거대한 블럭이나 개발자의 정신을 안드로메다로 보내버리는 무수한 셰이더 언어들의 단편을을 항상 필요로하는 것은 아니기 때문에, 이것이 제공하는 유연성은 더 복잡하고 동적인 셰이더 코드를 개발하는 것을 가능케 할 것입니다. 셰이더의 성능은 여전히 제약되어 있고, 그 결과물 또한 제한적이지만, 새로운 DX는 개발에 있어 장해요소가 되는 코드의 복잡성을 줄일 수 있도록 도와줄 것입니다.
비순차적Unordered 메모리 엑세스, 멀티 쓰레딩, 테셀레이션, 그리고 연산 셰이더를 수행하는 능력과 함께 DX11은 상당한 매력을 가지고 있습니다.
하지만 이 변화의 복잡함은 DX9에서 DX10으로의 이행과 같이 대대적은 변화는 아닙니다. 기능의 면에서 보았을 때 DX11은 DX10의 정밀 개선판에 지나지 않는 것입니다. 이러한 특징이 HLSL과 함께 OOP와 동적 셰이더 연계를 통해 기존의 하드웨어에서 DX11을 사용할 수 있도록 해주며, 이는 DX9에서 이행할 때와는 달리 주저없이 개발자들이 DX10에서 DX11으로 갈아 탈 수 있게 해 줄 것입니다. (최초의 DX8 기반 게임이 나온 것은 DX9가 발표된 이후였고, DX10이 나온 후에서야 DX9기반의 게임들이 늘어나기 시작한 만큼, 즉각적인 변화는 없을 것입니다.)
OS 업그레이드 필요성 역시 따져볼 문제입니다.
이번에는 그다지 문제가 되지 않는 것이, 비스타는 여전히 병맛이지만 DX11 지원을 받을 수 있을 것이고, 윈도우즈 7은 XP사용자들에게 조금 더 나은 선택지처럼 보이니까요. 아직까지 DX9를 사용하고 있는 개발자들도 그들의 게임 발매 일정을 예측하여 DX10을 바로 건너뛰어 DX11으로 갈아타도 될 것입니다. 모든 정황이 언제쯤 DX10으로 이행하는 변혁을 볼 수 있게 될지 미리 이야기해 주고 있는 듯 합니다. 개발자들은 DX10의 확장된 기능과 프로그래밍 능력에 스스로 적응하는 기간을 거쳤고, OOP 구조와 멀티 쓰레드가 매력적이지 않다고해도 DX11의 코딩이 훨씬 간단하고, 이전의 하드웨어에서 보다 나은 코딩 환경을 제공하는 것 때문에 갈아타는 것을 주저하지 않을 것입니다.



비스타 실패하고 7을 밀어줄려면 다렉11로 제대로 지원해주겠다는 의도도 보이는데... 어둠의 비스타와 다렉10이 탈생할 수도...
번역 수고하셧습니다! 고생하셧어요!



그보다 소프트웨어 개발자들에게 다이렉트X 11의 이점을 각인시켜줘야 하겠지만...
덕분에 많은 내용 잘 배워갑니다~ 수고하셨어요~ ^^

DX9->10과 달리 정밀화된 버전이라는 것, 지오메트리를 테셀레이터로 보완한다는 것, 멀티 쓰레드의 활성화 정도인가요?
덧. 마지막 문단에 비스타는 여전히 병맛..
 이네스
이네스
저 같은 초보 DB개발자들은 명함도 못내밀겠군요. 일반 언어쪽과 달리 용어도 생소한 것이 많고요.
개발자도 다 같은 개발자가 아니라는 생각이 듭니다.
d3d9 까지는 범용적이고 제대로된 게임용 API 라고 보기엔 미약한 수준입니다. (API 기능을 다 쓰지 못함, 게임 개발에서는 당연히 Nvidia 가 유리할수 밖에 없음)
http://gigglehd.com/zbxe/?mid=bbs&search_target=title&search_keyword=dx&document_srl=1192691

비스타, DX10 -> 이전 버젼에서 획기적으로 달라졌지만 여러가지 큰 문제가 많아 XP와 DX9에게 발림.
세븐, DX11 -> 이전 버젼의 문제점을 살짝 개선하고 XP와 DX9를 대체할 준비를 착실히 하고 있음
정도가 되려나요?;;

영어 실력도 출중하지 못하고 해서 제가 보고싶은데만 땀 뻘뻘 흘려가며 번역해서 봤었는데...
좋은 정보 잘보고가요 감사드려요^^;;;
 루다링
루다링
개인적인 생각인데요... DX11과 R600/rv670계열 그리고 rv700계열의 테셀레이터는 모두 프로그램가능하다고 하네요
(DX11에서 사용된 테셀레이션 개념도 Ati에서 제공한것을 확장한거나 마찬가지니...)
정점을 단순히 확장만하는 테셀레이션 개념이라면 이미 전에 나왔던 트루폼이에요...
트루폼은 정점확장에 있어서 프로그램 가능한게 없어서 몇몇 게임에서는 필요없는것까지 동글동글하게 만들어버린 전례가
있었다고 하네요.
hd4000번대와 hd3000/2000번대의 테셀레이터가 구조적으로 다르다는 이야기도 들은거같아요.
아무튼간에 Ati의 테셀레이터가 dx11에서 사용가능하느냐 마느냐는 대부분 실제 DX11이 나와봐야 알꺼같다는
분위기가 많은거같아요..
 andu
andu
음...기존 DX10하드웨어에서 DX11를 어느정도 맛볼수 있는거군요 ㅇㅅㅇ...
중반부터 졸려...ㅠㅠ
(dx11의 파이프는 버텍스-(헐-테셀레이터-도메인)-지오메트리 순이에요.)
4000번대부터는 테셀레이터에서 버텍스를 안거치고 지오메트리 쉐이더로 직접 데이터 전송이 가능해졌다고해요.
(3000번대 이전세대는 어떻게 되는지는 모르겠어요.)
그래서 dx11의 파이프라인 흐름대로 데이터를 이동시킬수 있을거같아요. 그러나
컴퓨트 쉐이더등의 다른쪽에서 몇가지 요건을 충족시키지 못하기 때문에
dx10.1이라는 타이틀을 그대로 달고있을가능성이 높을꺼같아요.

